标签 - ElasticSearch
ElasticSearch
2018-09-01 00:41:33
1
0
0
GET /_cluster/health 查询集群健康状态
添加一个节点
直接启动另外一个节点应用,只要确保在另一个节点中的cluster name相同,且discovery.zen.ping.unicast.hosts这个配置指向每台的节点的IP
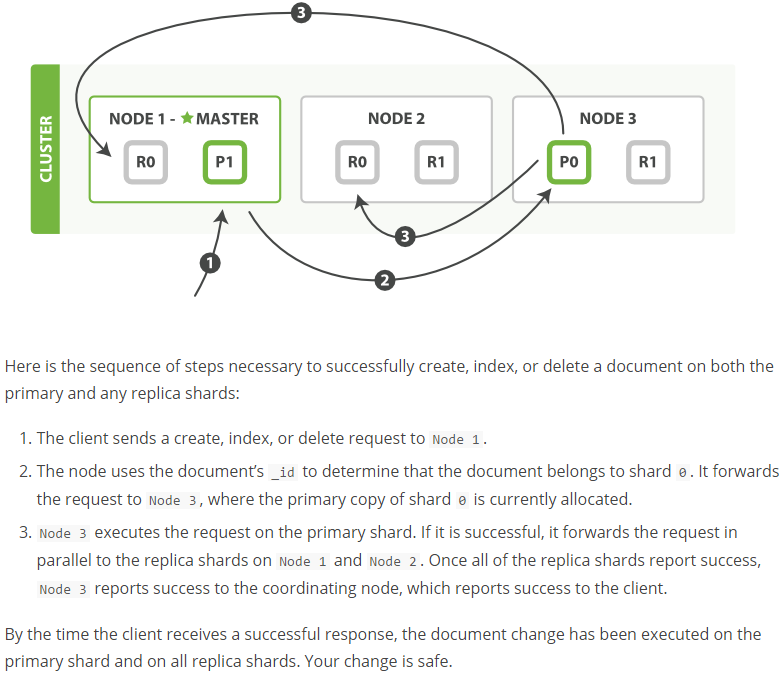
在集群环境中,对文档进行index、create、delete流程
在集群环境中,获得retri
ElasticSearch
2018-09-01 00:40:15
0
0
0
下载安装包,解压。设置JAVA_HOME环境,ES必须要JDK7以上的版本才能支持,并建议JDK7在55版本之后,JDK8在20版本之后。
经过以上步骤即可运行ES, 执行$ES_HOME/bin/elasticsearch
$ES_HOME/bin/elasticsearch -d 后台执行
$ES_HOME/bin/elasticsearch -d -p PID 将ES的pid写入P
ElasticSearch
2018-09-01 00:40:10
1
0
0
注册一个仓库
PUT /_snapshot/my_backup
{
"type": "fs",
"settings": {
... repository specific settings ...
}}PUT /_snapshot/backup
{
"type": "fs",
"settings": {
"location"
ElasticSearch
2018-09-01 00:40:07
17
0
0
添加索引
PUT /idx 添加名称叫做idx的索引,默认生成5个primary主分片及一个replica副本
当不需要保存源数据时,可设置_source为disable
PUT /my_index
{
"mappings": {
"my_type": {
"_source": {
ElasticSearch
2018-09-01 00:39:59
0
0
0
metadata 文档元数据
_index 保存文档的索引名。index只是一个逻辑概念,其实际是由主分片和副本分片组成
_type 文档所归属的类型。在index这个级别上,数据分类可能还太分散,此时需要_type进行细分。比如商品目录,需要将商品细分为电子、电脑、厨房等
_id 文档编号,可指定或ES生成
索引一个文档
PUT /{index}/{type}/{i
ElasticSearch
2018-09-01 00:39:56
2
0
0
每个文档都有个type属性,每个type都有其自己的映射(mapping)或模式定义(schema definition)。映射定义了每个字段的类型及该字段将如何解析
GET /gb/_mapping/tweet 查看mapping
主要的一些字段类型
- 文本:string
- 整型:byte、short、integer、long
- 浮点型:flo
ElasticSearch
2018-09-01 00:39:54
1
0
0
解析过程:
- 将一段文本拆分成一个个单词并将单词应用在倒排索引中
- 然后将这些单词进行标准化(如将所有字母转成小写)来提供可查性
解析器组成:
解析器实际是一个包装对象,其包含如下三个功能:
- character filters 文本过滤器。首先, 一段文本将按序传递给任意个的文本过滤器,它的工作就是在对文本进行分割之前进行调整,如将文本中的html元素删除等
ElasticSearch
2018-09-01 00:39:52
0
0
0
shard是es中的名称,在lucene中叫index。以下皆是lucene中的索引运行原理。
每个segment都是一个inverted index倒排索引,index索引实际是由1到多个的segment组成,在index层次上,有个commit point提交点,其包含当前生效的所有的segment的名称。在查询时,lucene将按照segment从旧到新的顺序加载所有数据
ElasticSearch
2018-09-01 00:39:50
0
0
0
查询结构:
_search
|---query
| |----match_all
| |----match
| | |----field ({ "match": { "tweet": "About Search" }})
| |
ElasticSearch
2018-09-01 00:39:47
0
0
0
聚合中有两个重要的概念:
Bucket : 桶,一类数据的集合。在传统数据概念上就是分组的意思。Bucket中可以再嵌套Bucket,不限深度。
Metric:指标,对一"bucket"中的数据进行统计(最小值、最大值、平均值、求和)
具体示例:
GET /cars/transactions/_search
{
"size" : 0,
"aggs":{
"po